오늘은 여섯 번째 정렬 알고리즘이자, 시간 복잡도가 O(N+K)인 특이한 정렬 알고리즘. 계수정렬(Counting sort)에 대해 알아보겠습니다.
1. 데이터의 범위를 전부 표현가능한 자료구조(배열,리스트 whatever)를 준비한다. 2. 데이터를 한 번 순회하면서 각 값의 갯수를 세어준다. 3. 알게 된 갯수만큼 데이터를 저장하거나 출력하면 정렬이 끝!
기존의 정렬들과는 달리 딱 한 번만 데이터를 순회하면 정렬이 완료됩니다.
그림과 함께 정렬의 순서를 확인 해보겠습니다.
정렬 되기 전의 상태
1~5 범위의 데이터가 무작위로 준비되어 있습니다.
데이터를 전부 표현 가능한 5 사이즈의 배열을 준비했습니다.
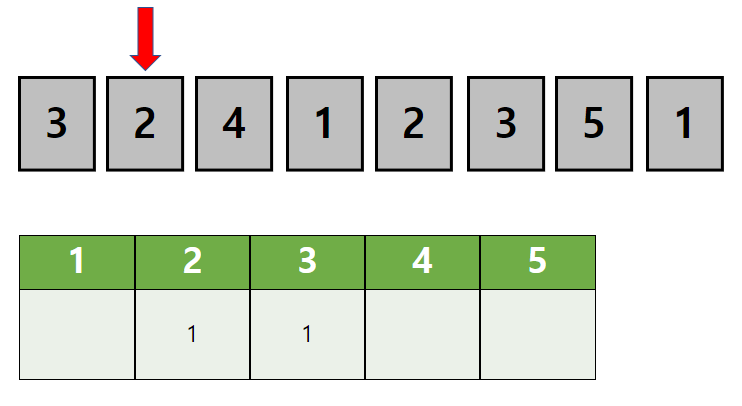
정렬되지 않은 첫 데이터의 값은 3입니다.
값을 셀 배열에서 3의 값을 의미하는 위치의 값을 1 증가시킵니다.
두번째 데이터의 값은 2입니다.
마찬가지로 배열에서 2의 위치의 값을 1 증가시킵니다.
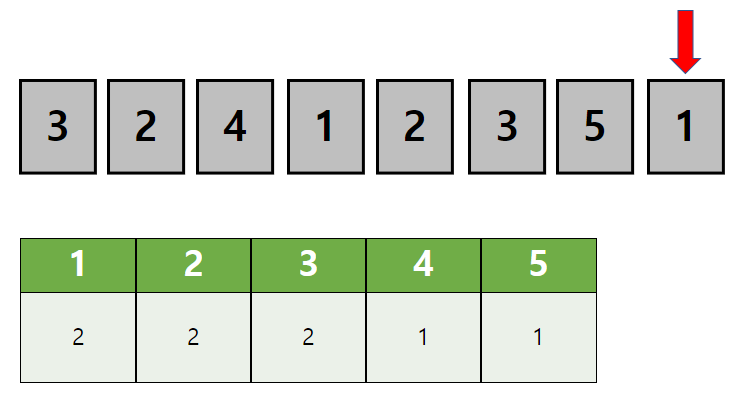
이런 방법으로 데이터를 한 번 순회하면...
위 처럼 정렬되지 않은 데이터가 몇개의 값으로 이루어진지 알 수 있습니다.
데이터의 값의 갯수를 모두 확인했다!
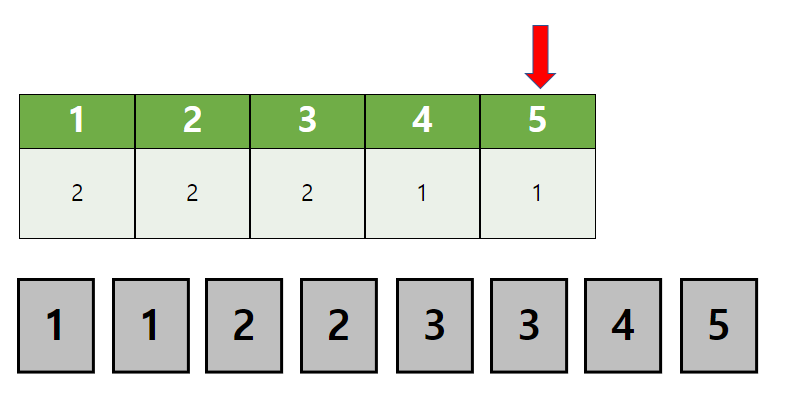
이제 값을 센 결과를 통해 정렬된 데이터를 만들어 봅시다.
1의 값을 가진 데이터가 2개이니 2개를 출력(혹은 정렬 후의 배열에 저장)
2의 값을 가진 데이터의 갯수도 2개이니 똑같이 출력
같은 작업을 끝까지 해주면 짠! 하고 정렬된 데이터를 얻게 됩니다.
이해하기도 쉽고 구현도 쉽고 시간복잡도까지 빠른 정렬 알고리즘입니다.
하지만 계수정렬은 특정 상황에서만 유용하게 쓰입니다.
시간복잡도 O(N+K)에서 알 수 있듯, K값인 데이터의 범위에 따라 그 효율성이 크게 달라지기 때문입니다.
예를 들어, 100명이 100점 만점의 시험을본 점수결과 데이터를 정렬한다고 해봅시다.
K값은 100이고 이 데이터를 정렬하는데엔 대략 200번의 연산이면 충분할겁니다.
반면 100명의 연봉 데이터를 정렬한다고 해봅시다.
100명중에 능력있는 프로그래머가 한 명 있어서 최댓값이 1억이라고 생각해보면 K값은 1억이 되고 이 데이터를 정렬하는데엔 약 1억번의 연산이 필요합니다!
범위가 1억이다!
같은 100개의 데이터를 정렬하는데 효율성이 엄청나게 차이가 나죠.
따라서 계수정렬은 특정 상황에서만 유용하게 쓸 수 있는 정렬알고리즘입니다.
아래는 간단하게 계수정렬을 구현한 JAVA코드 입니다.
디버깅 해보시며 정렬의 흐름을 따라해보시길 바랍니다.
import java.util.Arrays;
import java.util.Random;
public class sort_06_counting {
static int size = 50;
static int bound = 10;
static int count = 0;
// 데이터의 갯수와 범위 설정
public static void main(String[] args) {
int[] data = new int[size];
Random random = new Random();
for (int i = 0; i < size; i++) {
data[i] = random.nextInt(bound);
}
// 랜덤 값 넣어주기
System.out.println(Arrays.toString(data));
// 랜덤하게 들어간 데이터 확인
//////////////// 계수정렬 구현코드는 하단으로 /////////////////
countingSort(data, bound);
//////////////////////////////////////////////////////
System.out.println(Arrays.toString(data));
System.out.println("비교횟수 : " + count);
}
private static void countingSort(int[] data, int bound) {
int[] countingsort = new int[bound + 1];
int idx = 0;
for (int i = 0; i < data.length; i++) {
countingsort[data[i]]++;
count++;
}
for (int i = 0; i < bound; i++) {
count++;
for(int j = 0; j < countingsort[i]; j++) {
data[idx++] = i;
}
}
}
}
오늘은 네 번째 정렬 알고리즘이자, 시간 복잡도가 O(NlogN)인 첫 번째 정렬 알고리즘.
병합정렬에 대해 알아보겠습니다.
1. 데이터들이 한 개씩 쪼개어질 때까지 주어진 데이터를 두 개의 그룹으로 나누는 작업을 반복한다.
2. 하나씩 쪼개어진 데이터는 정렬된 상태가 된다.
3. 정렬된 데이터들을 쪼갠 역순으로 병합하면서 정렬하면 정렬된 상태의 전체 데이터를 구할 수 있다.
처음 병합정렬의 설명을 말로만 들으면 머릿속으로 정렬 과정을 그리기 쉽지 않을 텐데요.
그림을 통해 실제로 정렬이 이루어지는 과정을 보면서 설명하고 정리해드리도록 하겠습니다.
정렬 시작 전의 상태
언제나처럼 정렬되지 않은 데이터가 있습니다.
3, 5, 7, 4, 2, 6, 8, 1의 여덟 데이터를 정렬해보도록 하겠습니다.
우선 데이터들을 두 개의 그룹으로 나누는 과정을 반복하여, 하나씩 쪼개어줍니다.
이번 예시의 경우엔 데이터의 개수가 2^3인 8개이므로 3번의 단계를 거쳐서 쪼개어집니다.
이렇게 최종적으로 쪼개어진 밑단의 데이터들은 자연스럽게 정렬된 상태가 됩니다!
(데이터가 하나이기 때문에 당연히 정렬된 상태입니다.)
병합의 첫번째 단계
이제 부분적으로 정렬된 데이터들을 병합하는 첫번째 단계가 시작됩니다.
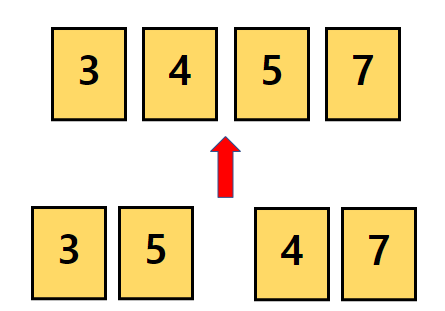
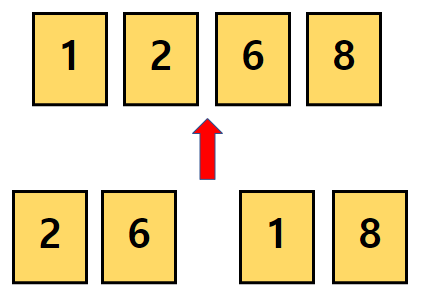
각각 정렬된 상태인 3과 5를 비교하여 병합합니다.
(두 데이터 그룹이 부분적으로 정렬된 상태이기때문에 앞에서부터 읽어들이면 됩니다.)
같은 방법으로 7과 4를 병합합니다.
병합의 첫번째 단계가 완료되었습니다.
이렇게 첫번째 병합이 완료되었습니다.
두번째 단계부턴 두개의 그룹이 병합되는 과정을 설명해보겠습니다.
병합의 두번째 단계
우리는 이미 부분적으로 정렬된 3,5 그리고 4,7의 그룹을 가지고 있습니다.
각 그룹이 이미 정렬된 상태기 때문에 전체를 탐색할 필요 없이 두 그룹의 가장 앞의 수를 보고 더 작은 수를 고르면 됩니다.
3과 4를 비교해 3을, 5와 4를 비교해 4를, 5와 7을 비교해 5, 마지막으로 남은 7을 골라줍니다.
자연스럽게 두개의 그룹이 정렬된 상태로 합쳐집니다.
그리고 두개의 그룹을 합칠 때 비교횟수는 전체 데이터의 갯수만큼이면 충분합니다!
(한 번의 비교에서 한개의 데이터가 골라집니다.)
같은 방법으로 나머지 그룹도 병합을 진행시켜줍니다.
마지막 세번째 병합 단계
이제 마지막, 세번째 병합을 똑같이 진행해줍니다.
두개의 그룹이 각각 부분적으로 정렬된 상태이기 때문에 앞에서부터 비교해가면서 합쳐주면 됩니다.
정렬이 완료되었습니다!
이렇게 병합정렬을 통한 정렬이 완료되었습니다!
이건 이해를 돕기 위한 예시일 뿐 실제 코드와 프로그램에선 재귀적으로 파고들어 가며 정렬이 진행되기 때문에 동작 흐름은 다릅니다.
병합정렬의 시간 복잡도가 왜 NlogN인지 간단하게 설명해보겠습니다.
앞서 배운 정렬들에서 우리는 각 단계마다 비교를 N, N-1, N-2... 번씩 수행하였고 N^2번의 비교가 필요함을 알았습니다.
병합정렬의 경우에는 각 단계별로 N번의 비교가 이루어집니다.
하지만 이 단계는 N번 반복되는 것이 아니라, N의 Log2값을 취한 만큼 이루어집니다.
데이터가 2^10개인 1024개라고 생각해봅시다.
처음 분할 단계에서 데이터는 2개의 그룹으로 나뉘는 일을 10번 반복하여 1개씩 1024개로 쪼개집니다.
그리고 이 데이터들은 10번의 단계를 거쳐 정렬된 1024개의 데이터가 됩니다.
10 * 1024 = 10,240번의 비교를 통해 정렬이 완료되는 겁니다.
버블정렬의 경우 같은 데이터에 대해 523,776번의 비교가 필요한 걸 생각하면, 또 데이터의 개수가 늘어날수록 이 차이가 더 커질 거란 걸 생각하면 NlogN정렬 알고리즘들이 더 효율적인걸 알 수 있습니다.
아래는 JAVA로 구현한 간단한 병합정렬 코드와 테스트입니다!
ArrayList 자료구조를 이용해 만들어봤는데요, 제가 적당히 작성한 코드라 실제 효율적인 부분에선 좋지 않을 것 같습니다!
병합정렬의 작동원리를 이해한다 정도로만 봐주시면 감사하겠습니다!
이것저것 바꿔보고 디버깅하면서 흐름이 이해되시길 바랍니다.
import java.util.ArrayList;
import java.util.Random;
public class sort_04_merge {
static int size = 10;
static int bound = 1000;
static int count = 0;
// 데이터의 갯수와 범위 설정
public static void main(String[] args) {
ArrayList<Integer> data = new ArrayList<Integer>();
Random random = new Random();
for (int i = 0; i < size; i++) {
data.add(random.nextInt(bound));
}
// 랜덤 값 넣어주기
System.out.println(data.toString());
// 랜덤하게 들어간 데이터 확인
//////////////// 병합정렬 구현코드는 하단으로 /////////////////
data = mergeSort(data);
//////////////////////////////////////////////////////
System.out.println(data.toString());
System.out.println("비교횟수 : " + count);
}
private static ArrayList<Integer> mergeSort(ArrayList<Integer> list) {
int size = list.size();
ArrayList<Integer> mergeList = new ArrayList<>();
if (size <= 1) {
return list;
} else {
ArrayList<Integer> left = new ArrayList<>();
ArrayList<Integer> right = new ArrayList<>();
for (int i = 0; i < (size / 2); i++) {
left.add(list.get(i));
}
for (int i = (size / 2); i < size; i++) {
right.add(list.get(i));
}
left = mergeSort(left);
right = mergeSort(right);
//System.out.println("left : " + left.toString());
//System.out.println("right : " + right.toString());
for (int i = 0, l = 0, r = 0; i < size; i++) {
if (r == right.size() || (l != left.size() && left.get(l) <= right.get(r))) {
mergeList.add(left.get(l));
l++;
} else {
mergeList.add(right.get(r));
r++;
}
count++;
}
//System.out.println("merge : " + mergeList.toString());
return mergeList;
}
}
}
보통 언어의 기본 라이브러리 안에서 구현이 되어있어 호출로 간단히 사용할 수 있지만 직접 구현해야 하는 경우도 있고 무엇보다 어떤 식으로 돌아가는지를 알아야 다른 방법으로도 활용할 수 있습니다.
오늘은 정렬 중에서도 가장 쉽게 구현 가능한 버블정렬에 대해 알아보겠습니다.
버블정렬의 아이디어는 간단합니다.
1. N개의 데이터가 있을 때, N-1번의 비교를 통해 가장 뒤에 (방향에 따라 달라집니다.) 위치할 데이터를 알아내자.
2. 이제 하나의 데이터는 자기 자리에 있으니 나머지 N-1개의 데이터를 가지고 비교를 해보자.
3. 정렬이 완료될 때까지 계속 반복하자!
그럼 한 번 비교가 이루어질때마다 1개씩 정렬되므로 N-1, N-2, N-3 ... 2,1 번 비교를 해야 합니다.
전체적인 비교의 횟수는 (N*(N-1))/2가 되는데, 시간 복잡도를 말할 때는 보통 작은 차수나 계수를 지우고 표현하기 때문에 O(N^2)와 같이 나타냅니다.
예를 들어 시간 복잡도가 2N인 프로그램과 3N인 프로그램, N^2번인 프로그램이 있다고 생각해봅시다. 데이터의 개수 N이 5개이고 하나를 처리할 때 1초가 걸린다고 가정하면 각각의 프로그램은 실행되는데 10초, 15초, 25초가 걸리게 됩니다. 이렇게 보면 계수의 차이가 유의미해 보이지만 보통 처리해야 할 데이터의 개수는 적게는 수백 개에서 수십억 개까지 늘어납니다. 1만 개의 데이터를 처리한다고 생각해봐도 첫 번째 프로그램은 2만 초로 실행에 대략 5시간이 걸리고 두 번째 프로그램은 3만 초, 약 8시간이 걸립니다. 하지만 세 번째 프로그램은 2만 7천 시간, 1157일이 필요합니다. 자잘한 계수의 비교는 크게 의미가 없는 것이죠.
그림을 통해 버블 정렬의 진행을 알아보도록 하겠습니다.
정렬 시작 전의 상태
그림에선 8칸짜리 배열에 8,5,3,2,1,6,4,7의 값이 들어 있습니다.
버블정렬을 통해 이 배열의 데이터들을 오름차순으로 정렬해 보겠습니다.
첫 번째 데이터부터 차근차근 비교해봅시다.
8개의 데이터가 있으므로 첫 반복에서 우리는 N-1번, 즉 7번의 비교를 해야 합니다.
지금 보고 있는 데이터와 다음 데이터를 비교해 더 크다면 위치를 바꿔줍니다.
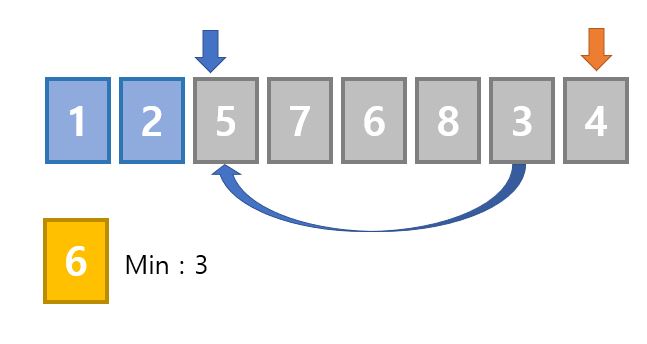
첫 번째 데이터인 8이 두번째 데이터인 5보다 크기 때문에 8과 5의 위치를 바꿔줍시다.
8과 3을 비교해 크다면 위치를 바꿉니다
이제 5와 8의 위치가 바뀌어 8이 두번째 데이터가 되었습니다.
두번째 데이터인 8과 다음 데이터 3을 비교해 더 크다면 둘의 위치를 바꿔줍시다.
8이 정렬된 모습
같은 방식으로 계속 비교를 해주고 위치를 바꿔주었더니 8이 가장 뒤에 위치하게 되었습니다.
첫번째 시행에서 우리는 N번째로 큰 수를 찾아서 N번 위치에 놓았습니다.
이로서 하나의 데이터가 자기 위치를 찾아 정렬되었고, N-1개의 정렬할 데이터가 남았습니다.
8은 이미 정렬되었으므로 5,3,2,1,6,4,7의 7개 데이터를 정렬해봅시다.
방법은 위와 똑같이 지금 보고 있는 수가 다음 수보다 크다면 자리를 바꿔줍니다.
지금 보는 수보다 다음 수가 크다면 바꾸지 않는다
비교를 진행하다 보니, 뒤의 수가 더 큰 경우가 나왔습니다.
지금 보고 있는 수 5보다 다음 수 6이 크다면 둘의 위치를 바꿔주지 않습니다.
위치를 바꾸지 않는다면, 다음 비교에서 우리는 자연스럽게 5보다 더 큰 수인 6을 기준으로 비교를 하게 됩니다.
5를 대신해 6이 자기보다 큰 수가 나타날 때까지 계속해서 위치를 바꾸게 됩니다.
마지막 비교에서 6보다 7이 크므로 둘의 위치는 바뀌지 않습니다.
이로서 두 번째 시행의 시작인 5,3,2,1,6,4,7중 가장 큰 수인 7을 찾았고 자신의 위치인 7번 자리에 7이 위치하게 됩니다.
이제 두 개의 수가 정렬되었고 우리는 N-2개의 수를 대상으로 다시 비교를 시작합니다.
이다음 시행은 과정을 기록하지 않겠습니다.
머릿속으로 테스트를 해보시고 정렬 후의 모습과 비교해보시기 바랍니다.
세번째 시행 후!네번째 시행 후!
네 번째 시행이 끝나고 나서 우리 눈으로 보기엔 정렬된 데이터가 완성되었습니다.
하지만 컴퓨터의 입장에선, 5 6 7 8 네 개의 데이터만 정렬되었다고 인식하므로 1,2,3,4에 대해서도 같은 시행을 반복하게 됩니다.
아래에는 JAVA로 구현한 간단한 버블정렬 코드와 테스트입니다!
이것저것 바꿔보고 디버깅하면서 흐름이 이해되시길 바랍니다.
import java.util.Arrays;
import java.util.Random;
public class 01_sort_01_bubble {
static int size = 100;
static int bound = 1000;
// 데이터의 갯수와 범위 설정
public static void main(String[] args) {
int[] data = new int[size];
Random random = new Random();
int count = 0;
for (int i = 0; i < size; i++) {
data[i] = random.nextInt(bound);
}
// 랜덤 값 넣어주기
System.out.println(Arrays.toString(data));
// 랜덤하게 들어간 데이터 확인
/////////////////////// 버블정렬 구현////////////////////////////
for (int find = size - 1; find >= 0; find--) {
for (int now = 0; now < find; now++) {
int next = now + 1;
if (data[now] > data[next]) {
int save = data[now];
data[now] = data[next];
data[next] = save;
}
count++;
}
}
//////////////////////////////////////////////////////
System.out.println(Arrays.toString(data));
System.out.println("비교횟수 : " + count);
// 정렬 후 데이터와 비교횟수 확인
int[][] data2 = { { 1, 1 }, { 3, 1 }, { 5, 1 }, { 7, 1 }, { 9, 1 }, { 1, 2 }, { 2, 2 }, { 4, 2 }, { 1, 3 },
{ 7, 2 }, { 9, 3 }, { 3, 3 }, { 4, 3 }, { 8, 3 }, { 6, 3 } };
for (int find = 14; find >= 0; find--) {
for (int now = 0; now < find; now++) {
int next = now + 1;
if (data2[now][0] > data2[next][0]) {
int[] save = data2[now].clone();
data2[now] = data2[next].clone();
data2[next] = save.clone();
}
}
}
for (int i = 0; i < 15; i++) {
System.out.printf("정렬된 수 : %d, stable: %d\n", data2[i][0], data2[i][1]);
}
//stable 정렬임!
}
}