순열은 어떤 집합의 원소들을 중복없이 뽑아 순서에 상관있게 나열하는것입니다.
n개의 원소를 가진 집합에서 r개를 뽑아 순열을 만든다고 하면 nPr 과 같이 나타냅니다.
원소를 넣을지 말지를 정했던 부분집합과 달리 순열은 이 위치에 이 원소를 넣을지 말지를 나누어서 진행됩니다.

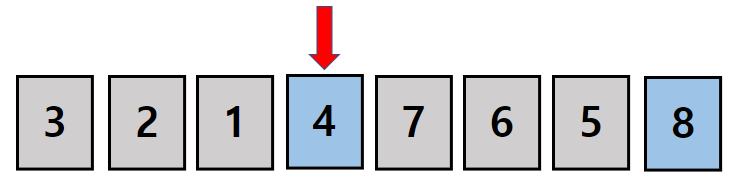
{1,2,3,4}로 4개의 원소를 가진 집합에서 4개를 뽑아 만들 수 있는 순열을 모두 구한다고 해봅시다. = 4P4
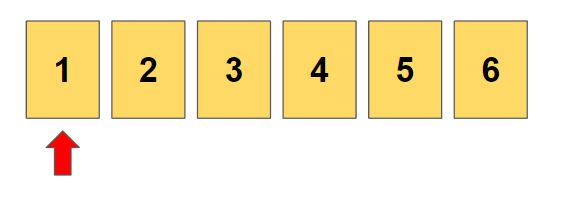
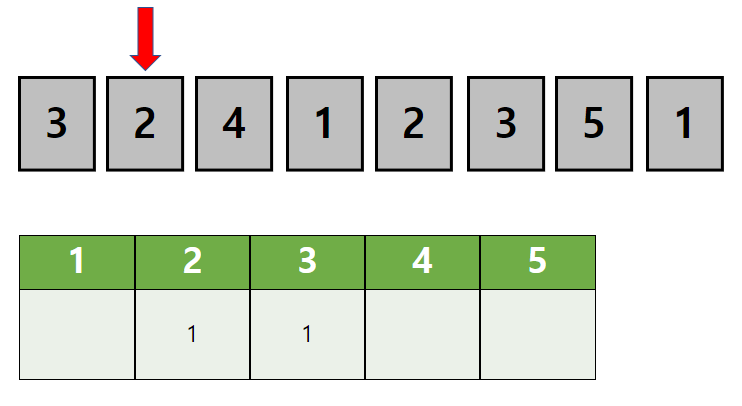
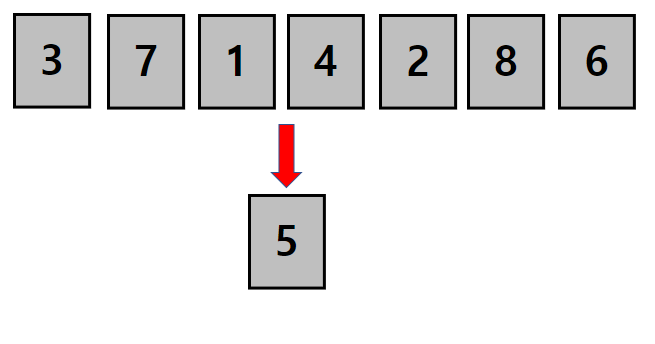
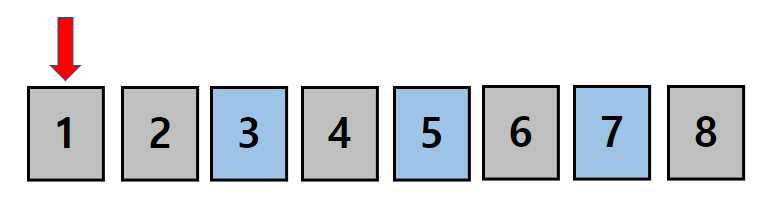
우선 첫번째 위치에 1이 들어갑니다.
이 과정에서 우리는 1로 시작하는 모든 순열을 구하게 됩니다. (1로 만들수 있는 경우)
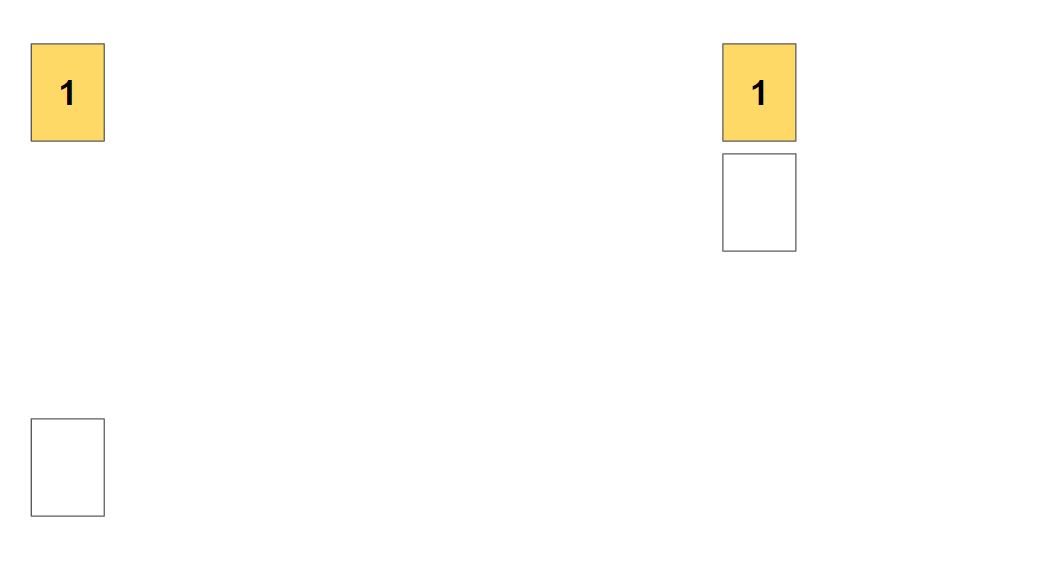
중복이 허용되지 않기 때문에 이미 사용된 1을 제외한 나머지 원소들 중에서 두번째 자리에 들어갈 것을 정해야합니다.
순서대로 2를 넣어줍니다. (1-2로 만들수 있는 경우)
같은 방식으로 중복이 되지 않게 다음 자리에 넣어질 수를 구해봅시다.
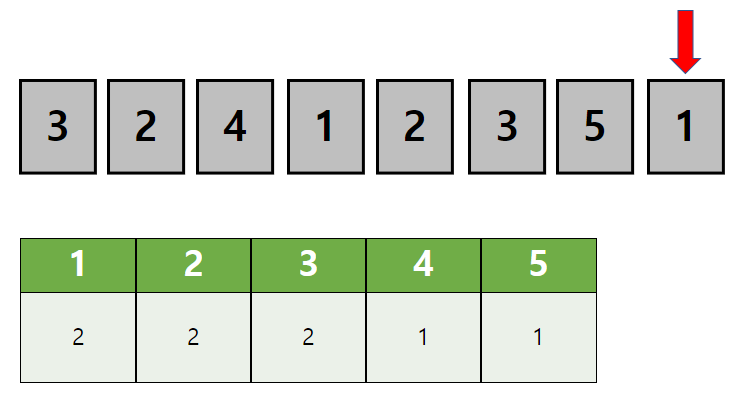
이때 재귀 호출된 함수는 이런 상태입니다.
가장 위쪽에서부터 하나씩 숫자를 선택하며 4번째 같은 함수를 호출했습니다.
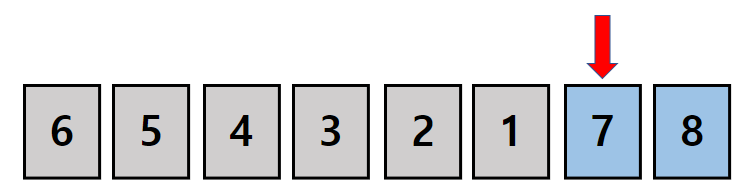
원했던 4개의 원소를 뽑았으므로 1-2-3-4 순열이 완성됩니다. (1-2-3 으로 만들수 있는 경우)
이제 4번째 함수는 종료되고 세번째 함수로 돌아갑니다. (1-2로 만들수 있는 경우)
세번째 자리에 3을 넣은 경우는 앞에서 시행했으므로 이번엔 4가 들어갑니다.
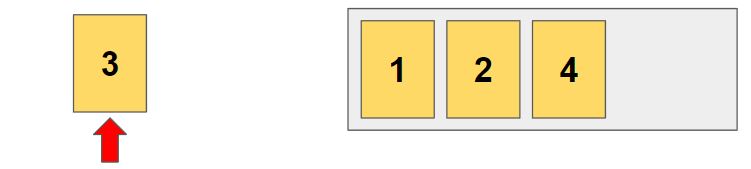

같은 방식으로 진행해서 이번엔 1-2-4-3 이라는 순열을 완성했습니다. (1-2-4 로 만들수 있는 경우)
순열은 구성한 원소가 같더라도 순서가 다르면 다른 것으로 보기때문에 1-2-3-4와 1-2-4-3은 다른 순열입니다.
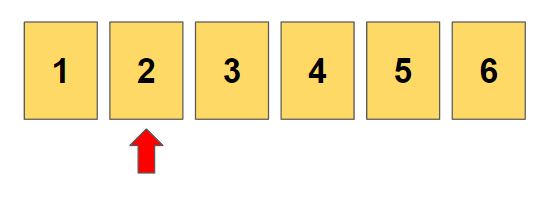
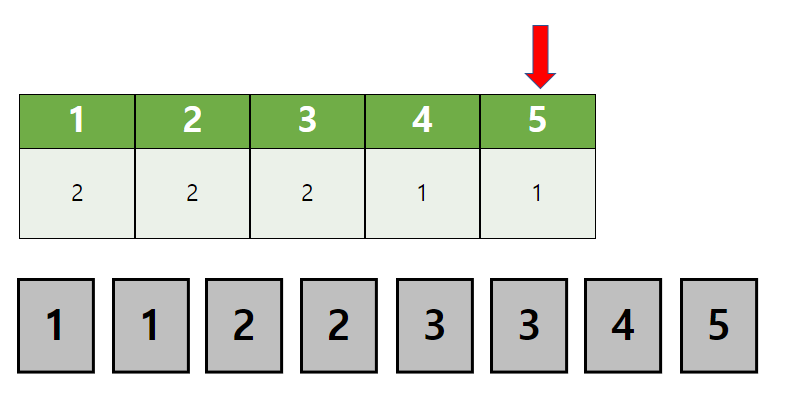
첫 자리와 두번째 자리가 각각 1, 2인 경우는 모두 탐색되었습니다.
이제 두번째 자리가 달라지는 경우를 찾습니다.
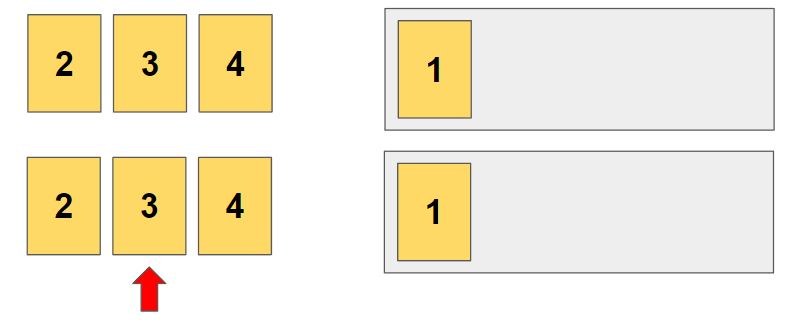
두번째 자리에 3이 들어가는 경우가 시작됩니다.
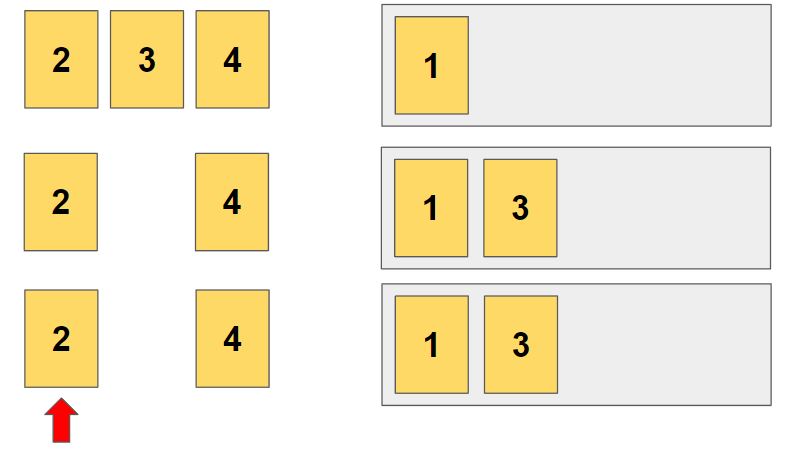
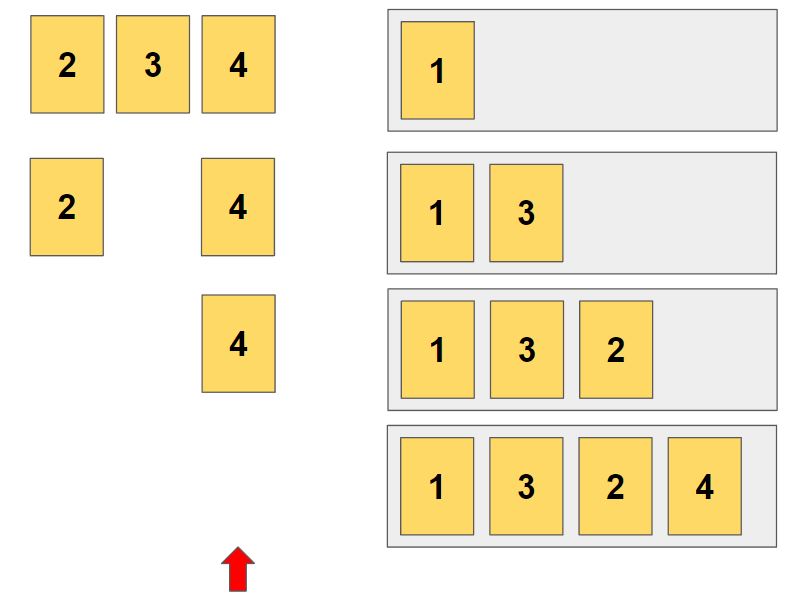
위와 같은 방식으로 진행해서 1-3-2-4 순열을 얻었습니다.

같은 방식으로 진행하면 위와 같은 순서로 24개의 순열을 얻습니다.
처음 시작할때 원소들이 오름차순 정렬된 상태였으므로 결과들도 오름차순으로 정렬된 순서로 나옵니다.
아래는 위 아이디어를 구현한 Java와 Python코드입니다.
size 변수를 number배열의 원소 갯수보다 작게 조절하면 부분순열이 됩니다.
순열을 만드는 방법은 아래와 같이 재귀를 이용한 것과 반복문을 이용한 nextPermutation이란것이 있는데 후자는 다른 포스팅에서 얘기해보도록 하겠습니다.
public class algo_02_permutation {
static int[] number = { 1, 2, 3, 4, 5, 6 };
static int size = 6;
public static void main(String[] args) {
makePermutation(0, new int[size], new boolean[number.length]);
}
public static void makePermutation(int count, int[] picked, boolean[] used) {
if (count == size) {
printPermutation(picked);
return;
}
for(int i = 0; i < number.length; i++) {
if(!used[i]) {
picked[count] = number[i];
used[i] = true;
makePermutation(count+1, picked, used);
used[i] = false;
}
}
}
public static void printPermutation(int[] picked) {
StringBuilder sb = new StringBuilder();
sb.append("{ ");
for (int i = 0; i < size; i++) {
sb.append(picked[i]).append(" ");
}
sb.append("}");
System.out.println(sb.toString());
}
}
def makePermutation(count, picked, used):
global size
global number
if(count == size):
printPermutation(picked)
return
for i in range(0, len(number)):
if(not used[i]):
picked[count] = number[i]
used[i] = True
makePermutation(count+1, picked, used)
used[i] = False
def printPermutation(picked):
global size
msg = "{ "
for i in range(0,size):
msg += str(picked[i])
msg += " "
msg += "}"
print(msg)
number = [1,2,3,4,5,6]
size = 6
makePermutation(0, [0]*size, [False]*len(number))'📖 CS > 💡 알고리즘' 카테고리의 다른 글
| [Algorithm] 07.부분집합 (Subset) (0) | 2022.07.18 |
|---|---|
| [Algorithm] 06.정렬 - 계수정렬 (Counting sort) (0) | 2022.04.21 |
| [Algorithm] 04.정렬 - 퀵정렬 (Quick sort) (0) | 2022.04.19 |
| [Algorithm] 04.정렬 - 병합정렬 (Merge sort) (0) | 2022.02.23 |
| [Algorithm] 03.정렬 - 삽입정렬 (Insertion sort) (0) | 2022.02.21 |