알고리즘 공부를 하며 배운 여러 자료구조, 알고리즘 등을 정리해보려고 합니다.
정렬 알고리즘들은 기본적인 알고리즘이자 정말 많이 활용되는 알고리즘입니다.
보통 언어의 기본 라이브러리 안에서 구현이 되어있어 호출로 간단히 사용할 수 있지만 직접 구현해야 하는 경우도 있고 무엇보다 어떤 식으로 돌아가는지를 알아야 다른 방법으로도 활용할 수 있습니다.
오늘은 정렬 중에서도 가장 쉽게 구현 가능한 버블정렬에 대해 알아보겠습니다.
버블정렬의 아이디어는 간단합니다.
1. N개의 데이터가 있을 때, N-1번의 비교를 통해 가장 뒤에 (방향에 따라 달라집니다.) 위치할 데이터를 알아내자.
2. 이제 하나의 데이터는 자기 자리에 있으니 나머지 N-1개의 데이터를 가지고 비교를 해보자.
3. 정렬이 완료될 때까지 계속 반복하자!
그럼 한 번 비교가 이루어질때마다 1개씩 정렬되므로 N-1, N-2, N-3 ... 2,1 번 비교를 해야 합니다.
전체적인 비교의 횟수는 (N*(N-1))/2가 되는데, 시간 복잡도를 말할 때는 보통 작은 차수나 계수를 지우고 표현하기 때문에 O(N^2)와 같이 나타냅니다.
예를 들어 시간 복잡도가 2N인 프로그램과 3N인 프로그램, N^2번인 프로그램이 있다고 생각해봅시다.
데이터의 개수 N이 5개이고 하나를 처리할 때 1초가 걸린다고 가정하면 각각의 프로그램은 실행되는데 10초, 15초, 25초가 걸리게 됩니다. 이렇게 보면 계수의 차이가 유의미해 보이지만 보통 처리해야 할 데이터의 개수는 적게는 수백 개에서 수십억 개까지 늘어납니다.
1만 개의 데이터를 처리한다고 생각해봐도 첫 번째 프로그램은 2만 초로 실행에 대략 5시간이 걸리고 두 번째 프로그램은 3만 초, 약 8시간이 걸립니다.
하지만 세 번째 프로그램은 2만 7천 시간, 1157일이 필요합니다.
자잘한 계수의 비교는 크게 의미가 없는 것이죠.
그림을 통해 버블 정렬의 진행을 알아보도록 하겠습니다.

그림에선 8칸짜리 배열에 8,5,3,2,1,6,4,7의 값이 들어 있습니다.
버블정렬을 통해 이 배열의 데이터들을 오름차순으로 정렬해 보겠습니다.

8개의 데이터가 있으므로 첫 반복에서 우리는 N-1번, 즉 7번의 비교를 해야 합니다.
지금 보고 있는 데이터와 다음 데이터를 비교해 더 크다면 위치를 바꿔줍니다.
첫 번째 데이터인 8이 두번째 데이터인 5보다 크기 때문에 8과 5의 위치를 바꿔줍시다.

이제 5와 8의 위치가 바뀌어 8이 두번째 데이터가 되었습니다.
두번째 데이터인 8과 다음 데이터 3을 비교해 더 크다면 둘의 위치를 바꿔줍시다.
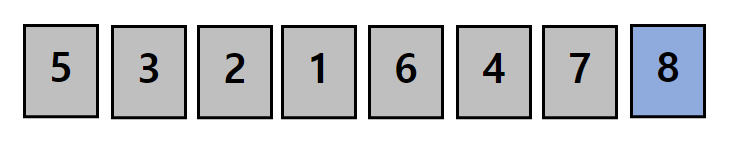
같은 방식으로 계속 비교를 해주고 위치를 바꿔주었더니 8이 가장 뒤에 위치하게 되었습니다.
첫번째 시행에서 우리는 N번째로 큰 수를 찾아서 N번 위치에 놓았습니다.
이로서 하나의 데이터가 자기 위치를 찾아 정렬되었고, N-1개의 정렬할 데이터가 남았습니다.

8은 이미 정렬되었으므로 5,3,2,1,6,4,7의 7개 데이터를 정렬해봅시다.
방법은 위와 똑같이 지금 보고 있는 수가 다음 수보다 크다면 자리를 바꿔줍니다.
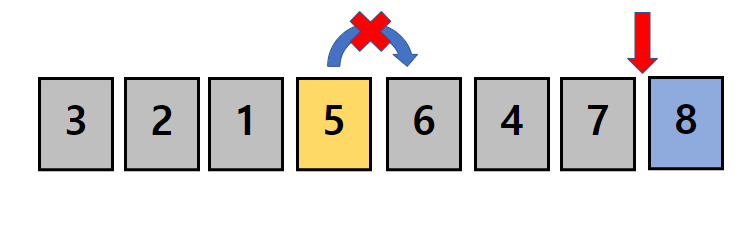
비교를 진행하다 보니, 뒤의 수가 더 큰 경우가 나왔습니다.
지금 보고 있는 수 5보다 다음 수 6이 크다면 둘의 위치를 바꿔주지 않습니다.

위치를 바꾸지 않는다면, 다음 비교에서 우리는 자연스럽게 5보다 더 큰 수인 6을 기준으로 비교를 하게 됩니다.
5를 대신해 6이 자기보다 큰 수가 나타날 때까지 계속해서 위치를 바꾸게 됩니다.

마지막 비교에서 6보다 7이 크므로 둘의 위치는 바뀌지 않습니다.
이로서 두 번째 시행의 시작인 5,3,2,1,6,4,7중 가장 큰 수인 7을 찾았고 자신의 위치인 7번 자리에 7이 위치하게 됩니다.

이제 두 개의 수가 정렬되었고 우리는 N-2개의 수를 대상으로 다시 비교를 시작합니다.
이다음 시행은 과정을 기록하지 않겠습니다.
머릿속으로 테스트를 해보시고 정렬 후의 모습과 비교해보시기 바랍니다.
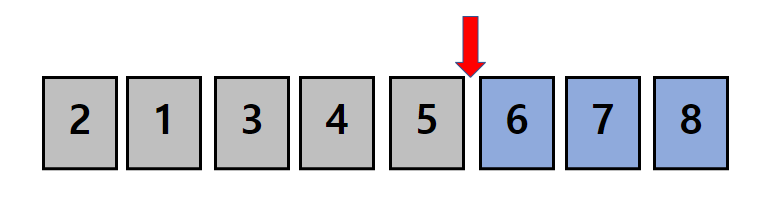
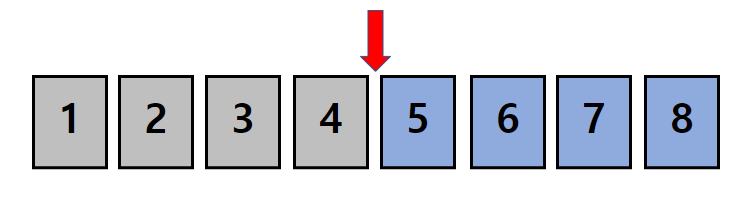
네 번째 시행이 끝나고 나서 우리 눈으로 보기엔 정렬된 데이터가 완성되었습니다.
하지만 컴퓨터의 입장에선, 5 6 7 8 네 개의 데이터만 정렬되었다고 인식하므로 1,2,3,4에 대해서도 같은 시행을 반복하게 됩니다.
아래에는 JAVA로 구현한 간단한 버블정렬 코드와 테스트입니다!
이것저것 바꿔보고 디버깅하면서 흐름이 이해되시길 바랍니다.
import java.util.Arrays;
import java.util.Random;
public class 01_sort_01_bubble {
static int size = 100;
static int bound = 1000;
// 데이터의 갯수와 범위 설정
public static void main(String[] args) {
int[] data = new int[size];
Random random = new Random();
int count = 0;
for (int i = 0; i < size; i++) {
data[i] = random.nextInt(bound);
}
// 랜덤 값 넣어주기
System.out.println(Arrays.toString(data));
// 랜덤하게 들어간 데이터 확인
/////////////////////// 버블정렬 구현////////////////////////////
for (int find = size - 1; find >= 0; find--) {
for (int now = 0; now < find; now++) {
int next = now + 1;
if (data[now] > data[next]) {
int save = data[now];
data[now] = data[next];
data[next] = save;
}
count++;
}
}
//////////////////////////////////////////////////////
System.out.println(Arrays.toString(data));
System.out.println("비교횟수 : " + count);
// 정렬 후 데이터와 비교횟수 확인
int[][] data2 = { { 1, 1 }, { 3, 1 }, { 5, 1 }, { 7, 1 }, { 9, 1 }, { 1, 2 }, { 2, 2 }, { 4, 2 }, { 1, 3 },
{ 7, 2 }, { 9, 3 }, { 3, 3 }, { 4, 3 }, { 8, 3 }, { 6, 3 } };
for (int find = 14; find >= 0; find--) {
for (int now = 0; now < find; now++) {
int next = now + 1;
if (data2[now][0] > data2[next][0]) {
int[] save = data2[now].clone();
data2[now] = data2[next].clone();
data2[next] = save.clone();
}
}
}
for (int i = 0; i < 15; i++) {
System.out.printf("정렬된 수 : %d, stable: %d\n", data2[i][0], data2[i][1]);
}
//stable 정렬임!
}
}'📖 CS > 💡 알고리즘' 카테고리의 다른 글
| [Algorithm] 06.정렬 - 계수정렬 (Counting sort) (0) | 2022.04.21 |
|---|---|
| [Algorithm] 04.정렬 - 퀵정렬 (Quick sort) (0) | 2022.04.19 |
| [Algorithm] 04.정렬 - 병합정렬 (Merge sort) (0) | 2022.02.23 |
| [Algorithm] 03.정렬 - 삽입정렬 (Insertion sort) (0) | 2022.02.21 |
| [Algorithm] 02.정렬 - 선택정렬 (Selection sort) (0) | 2022.02.17 |