우선 문제의 조건을 만족하도록 실패율을 구해줍니다. n번째 스테이지에 멈춰있는 인원이 Xn명이라면, n+1번째 스테이지에 도달한 인원은 n번째 스테이지에 도달한 인원 - nX명 이 됩니다.
즉, 첫 스테이지에는 모두가 도달했으므로 실패율이 (첫 스테이지에 멈춘 인원 / 전체 인원)이라면 두번째 스테이지는 (두번째 스테이지에 멈춘 인원 / (전체인원 - 첫 스테이지에 멈춘 인원)) 이 됩니다.
실패율을 계산해 주고, 만약 도달인원이 없다면 그냥 0으로 처리해주고 (divide zero 런타임 에러를 막기 위함) 얻은 실패율을 스테이지의 순서와 함께 묶어 리스트에 저장한 뒤 실패율을 기준으로 내림차순 정렬, 두번째 요소는 스테이지를 기준으로 오름차순 정렬을 해주면 됩니다.
fail_rate.sort(key=lambda x:(-x[0], x[1]))
x[0]이 실패율로 내림차순 정렬을 위해 마이너스 부호를 붙여주고, x[1]은 스테이지 번호로 오름차순 정렬이 됩니다.
def solution(N, stages):
answer = []
fail_rate = [[0, i+1] for i in range(N)]
stage_user = [0 for i in range(N+1)]
total_user = len(stages)
for stage in stages:
stage_user[stage - 1] += 1
for i in range(N):
if total_user == 0:
fail_rate[i][0] = 0
else:
fail_rate[i][0] = stage_user[i] / total_user
total_user -= stage_user[i]
fail_rate.sort(key=lambda x:(-x[0], x[1]))
for i in fail_rate:
answer.append(i[1])
return answer
print(solution( 5, [2, 1, 2, 6, 2, 4, 3, 3]))
예를 들어 2,8,1과 6,3,5가 입력으로 주어졌다고 가정해봅시다. 이를 각각 오름차순 내림차순으로 정렬하면 1,2,8과 6,5,3이 됩니다. 문제의 정답은 앞에서부터 순서대로 두 집합의 수를 곱한 6 + 10 + 24 = 40이 됩니다. 6,3,5의 배열이 바뀌었지만 1,2,8과 6,5,3의 곱의 위치를 바꾸어 1,8,2와 6,3,5로 생각해도 답은 같습니다. 그냥 적합한 순위의 수를 매번 찾기가 귀찮아 정렬해 놓았다고 생각해 버립시다.
아이디어가 맞는지 생각해 보겠습니다.
A에서 기존의 가장 작은 수를 a 라고 하면 a가 아닌 어떤 수는 a+c로 나타낼 수 있을겁니다. (a와 같을 수 있음, 즉 c≥0)
B에서 가장 큰 수를 b라고 하면 b가 아닌 어떤 수는 b-d로 나타낼 수 있을겁니다. (마찬가지로 d≥0)
아이디어가 틀리다면 다른 순서로 수를 배열했을때 합이 더 작아져야합니다.
다른 순서로 수를 배열한다면 기존의 (a * b) + ((a+c) * (b-d))가 (a * (b-d)) + ((a+c) * b)로 대체될겁니다.
각 식을 계산해 풀어주면 1. ab + ab + cb - ad - cd 와 2. ab - ad + ab + cb가 됩니다.
다른 수를 선택해서 합이 더 작아지는 케이스가 있다면 1번 식보다 2번 식이 더 작아야합니다.
즉 1번식 - 2번식 > 0 이 성립해야하는데, 계산해보면 cd < 0이 되고 c와 d는 각각 0 이상의 정수이기 때문에 성립하지 않습니다. (c와 d가 둘 다 0이라면 같은 크기일 순 있지만, 이때의 선택도 정답 조합의 하나가 됩니다.)
따라서 A에서 가장 작은 a와 B에서 가장 큰 b를 곱하는게 최소값이 되는 조합이고, 이렇게 fix된 a와 b를 제외한 A' B'로 다시 최소합을 구한다고 생각하면 같은 증명으로 A와 B의 크기가 1이 될 때까지 적용이 가능합니다.
둘의 크기가 1이라면 당연히 곱할 수 있는 방법이 하나밖에 없겠죠.
따라서 위와같이 정렬된 A와 역정렬된 B를 순서대로 곱한 합이 최소값입니다.
(제가 수학전공이 아니기 때문에 증명은 틀릴 수 있습니다... )
n = int(input())
A = list(map(int, input().split(' ')))
B = list(map(int, input().split(' ')))
A.sort()
B.sort(reverse=True)
answer = 0
for i in range(0,n):
answer += int(A[i]) * int(B[i])
print(answer)
핵심아이디어는 돈이 허락하는 범위 안에서 5000원짜리 메뉴를 먹었을때 얻는 상대적 만족도가 가장 큰 경우를 선택해야 한다는 것입니다.
예를 들어서, 극단적으로 5000원짜리 메뉴의 만족도가 1만이라고 해도 1000원짜리 메뉴의 만족도가 9999라면 상대적 만족도는 1에 불과합니다. 또 역으로 1000원짜리 메뉴가 더 만족스러운 경우도 가능할 수 있습니다.
가장 만족스러운 식사를 하려면 날짜와 만족도에 상관없이 상대적 만족도가 큰 5000원짜리 메뉴부터 골라서 가능한만큼 선택하는것이 해결방법입니다.
따라서 A메뉴와 B메뉴의 만족도의 차이를 기준으로 입력된 데이터를 정렬해주고, 돈이 허락하는 한에서 A메뉴를 선택했습니다. 돈이 가능한지 여부는 (골라야하는 남은 메뉴의 갯수 * 1000) + 4000 보다 현재 자금이 크거나 같으면 가능하다고 조건문을 잡아두었고 메뉴를 하나 고를때 마다 자금에서 5000원씩을 빼 주었습니다.
또, 정렬을 통해서 B메뉴의 만족도가 더 큰 시점이 오면 이후로는 전부 B메뉴를 선택했습니다. B메뉴를 선택하기 시작한 경우는 두가지입니다.
1. 돈이 부족해서 남은 모든 식사는 B메뉴로 골라야 한다. (조건문을 통해 보장됨)
2. 남은 모든 식사들은 B메뉴가 A메뉴보다 맛있다. (정렬을 통해 보장됨)
따라서 이후로는 돈 계산을 하지 않고 B메뉴의 만족도를 계속 더해주었습니다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.StringTokenizer;
public class Main {
static StringTokenizer st;
public static void main(String[] args) throws NumberFormatException, IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
long answer = 0;
st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int money = Integer.parseInt(st.nextToken());
int[][] menu = new int[N][2];
for (int n = 0; n < N; n++) {
st = new StringTokenizer(br.readLine());
menu[n][0] = Integer.parseInt(st.nextToken());
menu[n][1] = Integer.parseInt(st.nextToken());
}
Arrays.sort(menu, (e1, e2) -> {
return (e2[0] - e2[1]) - (e1[0] - e1[1]);
});
int n = 0;
while (money - ((N - n) * 1000) >= 4000) {
if(menu[n][1] > menu[n][0]) {
break;
}
answer += menu[n][0];
money -= 5000;
n++;
}
while (n < N) {
answer += menu[n][1];
n++;
}
System.out.println(answer);
}
}
오늘은 여섯 번째 정렬 알고리즘이자, 시간 복잡도가 O(N+K)인 특이한 정렬 알고리즘. 계수정렬(Counting sort)에 대해 알아보겠습니다.
1. 데이터의 범위를 전부 표현가능한 자료구조(배열,리스트 whatever)를 준비한다. 2. 데이터를 한 번 순회하면서 각 값의 갯수를 세어준다. 3. 알게 된 갯수만큼 데이터를 저장하거나 출력하면 정렬이 끝!
기존의 정렬들과는 달리 딱 한 번만 데이터를 순회하면 정렬이 완료됩니다.
그림과 함께 정렬의 순서를 확인 해보겠습니다.
정렬 되기 전의 상태
1~5 범위의 데이터가 무작위로 준비되어 있습니다.
데이터를 전부 표현 가능한 5 사이즈의 배열을 준비했습니다.
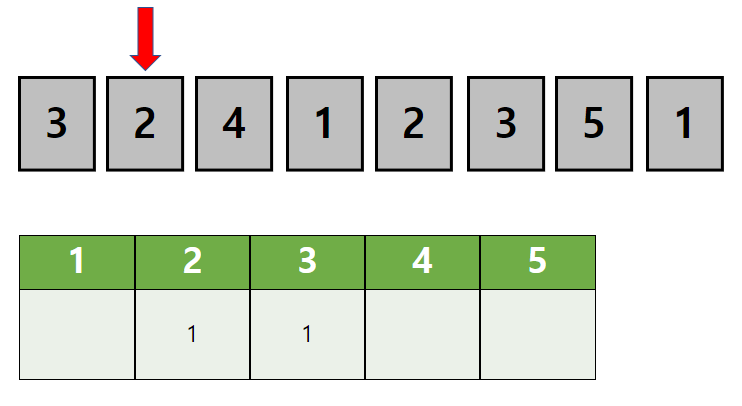
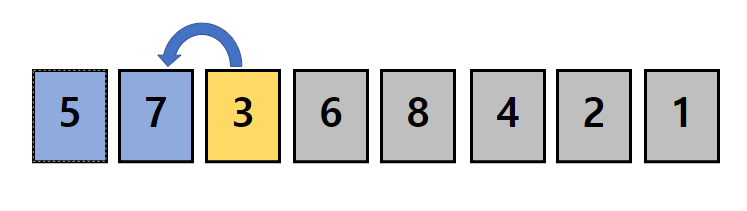
정렬되지 않은 첫 데이터의 값은 3입니다.
값을 셀 배열에서 3의 값을 의미하는 위치의 값을 1 증가시킵니다.
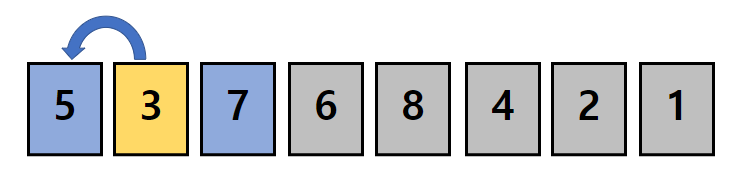
두번째 데이터의 값은 2입니다.
마찬가지로 배열에서 2의 위치의 값을 1 증가시킵니다.
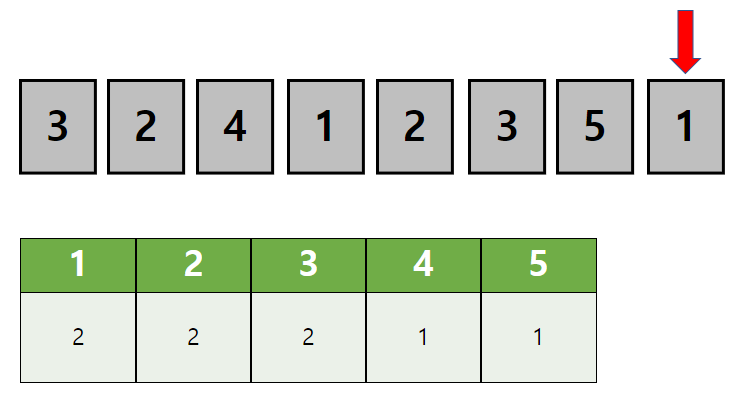
이런 방법으로 데이터를 한 번 순회하면...
위 처럼 정렬되지 않은 데이터가 몇개의 값으로 이루어진지 알 수 있습니다.
데이터의 값의 갯수를 모두 확인했다!
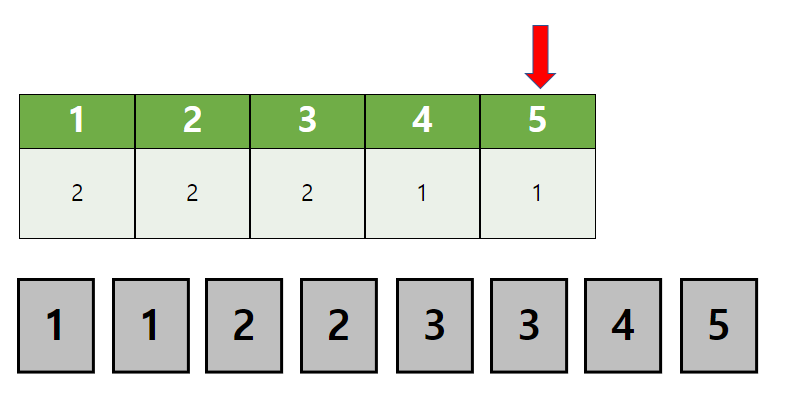
이제 값을 센 결과를 통해 정렬된 데이터를 만들어 봅시다.
1의 값을 가진 데이터가 2개이니 2개를 출력(혹은 정렬 후의 배열에 저장)
2의 값을 가진 데이터의 갯수도 2개이니 똑같이 출력
같은 작업을 끝까지 해주면 짠! 하고 정렬된 데이터를 얻게 됩니다.
이해하기도 쉽고 구현도 쉽고 시간복잡도까지 빠른 정렬 알고리즘입니다.
하지만 계수정렬은 특정 상황에서만 유용하게 쓰입니다.
시간복잡도 O(N+K)에서 알 수 있듯, K값인 데이터의 범위에 따라 그 효율성이 크게 달라지기 때문입니다.
예를 들어, 100명이 100점 만점의 시험을본 점수결과 데이터를 정렬한다고 해봅시다.
K값은 100이고 이 데이터를 정렬하는데엔 대략 200번의 연산이면 충분할겁니다.
반면 100명의 연봉 데이터를 정렬한다고 해봅시다.
100명중에 능력있는 프로그래머가 한 명 있어서 최댓값이 1억이라고 생각해보면 K값은 1억이 되고 이 데이터를 정렬하는데엔 약 1억번의 연산이 필요합니다!
범위가 1억이다!
같은 100개의 데이터를 정렬하는데 효율성이 엄청나게 차이가 나죠.
따라서 계수정렬은 특정 상황에서만 유용하게 쓸 수 있는 정렬알고리즘입니다.
아래는 간단하게 계수정렬을 구현한 JAVA코드 입니다.
디버깅 해보시며 정렬의 흐름을 따라해보시길 바랍니다.
import java.util.Arrays;
import java.util.Random;
public class sort_06_counting {
static int size = 50;
static int bound = 10;
static int count = 0;
// 데이터의 갯수와 범위 설정
public static void main(String[] args) {
int[] data = new int[size];
Random random = new Random();
for (int i = 0; i < size; i++) {
data[i] = random.nextInt(bound);
}
// 랜덤 값 넣어주기
System.out.println(Arrays.toString(data));
// 랜덤하게 들어간 데이터 확인
//////////////// 계수정렬 구현코드는 하단으로 /////////////////
countingSort(data, bound);
//////////////////////////////////////////////////////
System.out.println(Arrays.toString(data));
System.out.println("비교횟수 : " + count);
}
private static void countingSort(int[] data, int bound) {
int[] countingsort = new int[bound + 1];
int idx = 0;
for (int i = 0; i < data.length; i++) {
countingsort[data[i]]++;
count++;
}
for (int i = 0; i < bound; i++) {
count++;
for(int j = 0; j < countingsort[i]; j++) {
data[idx++] = i;
}
}
}
}
오늘은 네 번째 정렬 알고리즘이자, 시간 복잡도가 O(NlogN)인 첫 번째 정렬 알고리즘.
병합정렬에 대해 알아보겠습니다.
1. 데이터들이 한 개씩 쪼개어질 때까지 주어진 데이터를 두 개의 그룹으로 나누는 작업을 반복한다.
2. 하나씩 쪼개어진 데이터는 정렬된 상태가 된다.
3. 정렬된 데이터들을 쪼갠 역순으로 병합하면서 정렬하면 정렬된 상태의 전체 데이터를 구할 수 있다.
처음 병합정렬의 설명을 말로만 들으면 머릿속으로 정렬 과정을 그리기 쉽지 않을 텐데요.
그림을 통해 실제로 정렬이 이루어지는 과정을 보면서 설명하고 정리해드리도록 하겠습니다.
정렬 시작 전의 상태
언제나처럼 정렬되지 않은 데이터가 있습니다.
3, 5, 7, 4, 2, 6, 8, 1의 여덟 데이터를 정렬해보도록 하겠습니다.
우선 데이터들을 두 개의 그룹으로 나누는 과정을 반복하여, 하나씩 쪼개어줍니다.
이번 예시의 경우엔 데이터의 개수가 2^3인 8개이므로 3번의 단계를 거쳐서 쪼개어집니다.
이렇게 최종적으로 쪼개어진 밑단의 데이터들은 자연스럽게 정렬된 상태가 됩니다!
(데이터가 하나이기 때문에 당연히 정렬된 상태입니다.)
병합의 첫번째 단계
이제 부분적으로 정렬된 데이터들을 병합하는 첫번째 단계가 시작됩니다.
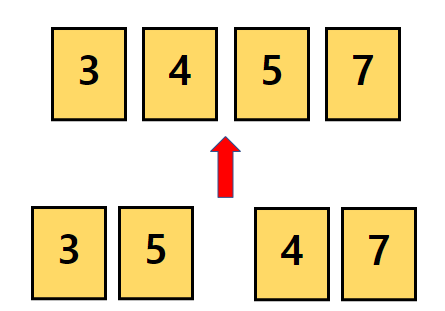
각각 정렬된 상태인 3과 5를 비교하여 병합합니다.
(두 데이터 그룹이 부분적으로 정렬된 상태이기때문에 앞에서부터 읽어들이면 됩니다.)
같은 방법으로 7과 4를 병합합니다.
병합의 첫번째 단계가 완료되었습니다.
이렇게 첫번째 병합이 완료되었습니다.
두번째 단계부턴 두개의 그룹이 병합되는 과정을 설명해보겠습니다.
병합의 두번째 단계
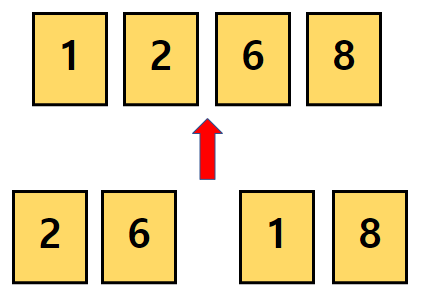
우리는 이미 부분적으로 정렬된 3,5 그리고 4,7의 그룹을 가지고 있습니다.
각 그룹이 이미 정렬된 상태기 때문에 전체를 탐색할 필요 없이 두 그룹의 가장 앞의 수를 보고 더 작은 수를 고르면 됩니다.
3과 4를 비교해 3을, 5와 4를 비교해 4를, 5와 7을 비교해 5, 마지막으로 남은 7을 골라줍니다.
자연스럽게 두개의 그룹이 정렬된 상태로 합쳐집니다.
그리고 두개의 그룹을 합칠 때 비교횟수는 전체 데이터의 갯수만큼이면 충분합니다!
(한 번의 비교에서 한개의 데이터가 골라집니다.)
같은 방법으로 나머지 그룹도 병합을 진행시켜줍니다.
마지막 세번째 병합 단계
이제 마지막, 세번째 병합을 똑같이 진행해줍니다.
두개의 그룹이 각각 부분적으로 정렬된 상태이기 때문에 앞에서부터 비교해가면서 합쳐주면 됩니다.
정렬이 완료되었습니다!
이렇게 병합정렬을 통한 정렬이 완료되었습니다!
이건 이해를 돕기 위한 예시일 뿐 실제 코드와 프로그램에선 재귀적으로 파고들어 가며 정렬이 진행되기 때문에 동작 흐름은 다릅니다.
병합정렬의 시간 복잡도가 왜 NlogN인지 간단하게 설명해보겠습니다.
앞서 배운 정렬들에서 우리는 각 단계마다 비교를 N, N-1, N-2... 번씩 수행하였고 N^2번의 비교가 필요함을 알았습니다.
병합정렬의 경우에는 각 단계별로 N번의 비교가 이루어집니다.
하지만 이 단계는 N번 반복되는 것이 아니라, N의 Log2값을 취한 만큼 이루어집니다.
데이터가 2^10개인 1024개라고 생각해봅시다.
처음 분할 단계에서 데이터는 2개의 그룹으로 나뉘는 일을 10번 반복하여 1개씩 1024개로 쪼개집니다.
그리고 이 데이터들은 10번의 단계를 거쳐 정렬된 1024개의 데이터가 됩니다.
10 * 1024 = 10,240번의 비교를 통해 정렬이 완료되는 겁니다.
버블정렬의 경우 같은 데이터에 대해 523,776번의 비교가 필요한 걸 생각하면, 또 데이터의 개수가 늘어날수록 이 차이가 더 커질 거란 걸 생각하면 NlogN정렬 알고리즘들이 더 효율적인걸 알 수 있습니다.
아래는 JAVA로 구현한 간단한 병합정렬 코드와 테스트입니다!
ArrayList 자료구조를 이용해 만들어봤는데요, 제가 적당히 작성한 코드라 실제 효율적인 부분에선 좋지 않을 것 같습니다!
병합정렬의 작동원리를 이해한다 정도로만 봐주시면 감사하겠습니다!
이것저것 바꿔보고 디버깅하면서 흐름이 이해되시길 바랍니다.
import java.util.ArrayList;
import java.util.Random;
public class sort_04_merge {
static int size = 10;
static int bound = 1000;
static int count = 0;
// 데이터의 갯수와 범위 설정
public static void main(String[] args) {
ArrayList<Integer> data = new ArrayList<Integer>();
Random random = new Random();
for (int i = 0; i < size; i++) {
data.add(random.nextInt(bound));
}
// 랜덤 값 넣어주기
System.out.println(data.toString());
// 랜덤하게 들어간 데이터 확인
//////////////// 병합정렬 구현코드는 하단으로 /////////////////
data = mergeSort(data);
//////////////////////////////////////////////////////
System.out.println(data.toString());
System.out.println("비교횟수 : " + count);
}
private static ArrayList<Integer> mergeSort(ArrayList<Integer> list) {
int size = list.size();
ArrayList<Integer> mergeList = new ArrayList<>();
if (size <= 1) {
return list;
} else {
ArrayList<Integer> left = new ArrayList<>();
ArrayList<Integer> right = new ArrayList<>();
for (int i = 0; i < (size / 2); i++) {
left.add(list.get(i));
}
for (int i = (size / 2); i < size; i++) {
right.add(list.get(i));
}
left = mergeSort(left);
right = mergeSort(right);
//System.out.println("left : " + left.toString());
//System.out.println("right : " + right.toString());
for (int i = 0, l = 0, r = 0; i < size; i++) {
if (r == right.size() || (l != left.size() && left.get(l) <= right.get(r))) {
mergeList.add(left.get(l));
l++;
} else {
mergeList.add(right.get(r));
r++;
}
count++;
}
//System.out.println("merge : " + mergeList.toString());
return mergeList;
}
}
}